
AppSheetは、automationを使ってファイルを簡単に作成できます。今回は、受注情報をPDFで作成して社内に展開する機能を作成していました。
明細の行頭に連番を自動で出力したい
現行業務は以下のように手書きの紙運用をしていたのですが、現行フォーマットはあらかじめ、行頭に行番号を示す連番が降られています。

AppSheetで受注データを登録する時は、データの追加/削除が発生します。
そのため、明細データ側に連番を持たせると、連番が飛び飛びにならないよう工夫するなど、懸念があります。
ファイル作成時に自動で明細に連番を付与する方法
帳票ヘッダ(親テーブル)と明細(子テーブル)の間の「[Related XXXXXXs]」リレーションを最大限に活用したて実現します。
以下のサイトを参考にさせて頂きました。
https://www.googlecloudcommunity.com/gc/AppSheet-Q-A/PDF-fortlaufende-Zeilennummerierung-auf-dem-Orderby-basiert/td-p/623868<<Start:Orderby(Nicht_Volljährig[MitgliedID],[Geburtsdatum])>><<COUNT(SPLIT(ANY(SPLIT((" , " & Nicht_Volljährig[MitgliedID] & " , "),(" , " &[MitgliedID] & " , ")))," ,"))>>
ファイル出力するデータの構成(ヘッダと明細)
実際の帳票では、帳票ヘッダと明細部に分けてデータを保持していると思います。
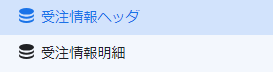
今回の例ですと、「受注情報ヘッダ」と「受注情報明細」が1:Nの関係となります。そのため受注情報明細に受注情報ヘッダを一意に特定する「伝票番号」をもち、Typeを「Ref」として「受注情報ヘッダ」と関連付けています。
受注情報明細の設定
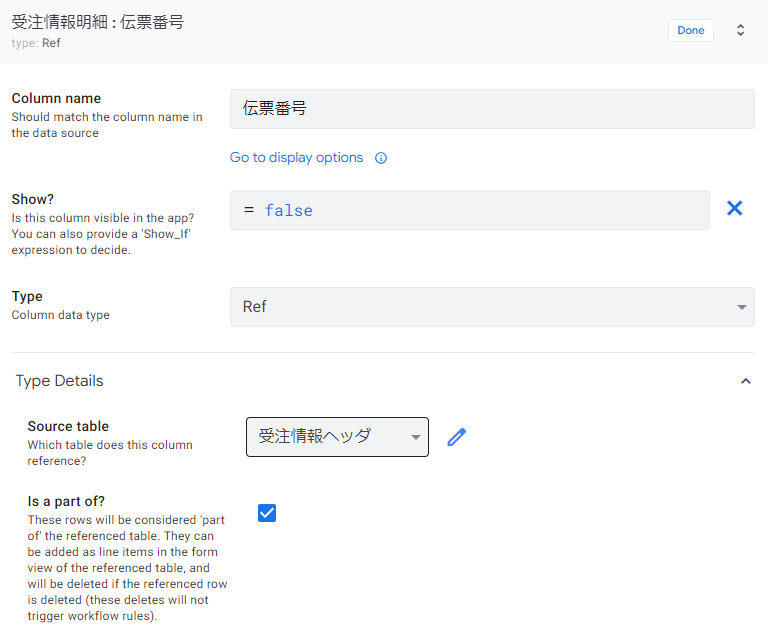
受注情報ヘッダの自動生成項目
受注情報ヘッダには、受注情報明細の設定により自動で「REF_ROWS(“受注情報明細”, “伝票番号”)」が生成され、紐づいている関係になります。「伝票番号」が主キーとなります。

ファイルに明細を出力する記述
この場合、automationで受注伝票に、受注明細データを出力するには、以下のように「[Related XXXXXXs]」を利用した「Start expressions」で、明細データを出力すると思います。
<<Start:Orderby([Related 受注情報明細s],[商品])>> … <<End>>そのため、今回は「[Related XXXXXXs]」を活用して、明細の自動連番を採番したいと思います。
明細行に連番を振る方法
最初に、今回の方法で出力したPDFの結果です。行頭の「#」に連番が振られていることが分かります。

上記を行うために用いた「Start expressions」は以下の通りです。
<<Start:Orderby([Related 受注情報明細s],[商品])>><<COUNT(SPLIT(ANY(SPLIT((" , " & (Orderby([Related 受注情報明細s][商品],[Related 受注情報明細s][商品])) & " , ") ,(" , " &[商品] & " , ")))," ,"))>>
<<[商品].[JANコード]>>
<<[商品].[商品名]>>
<<[数量]>><<End>>ポイントは、最初の参考サイトの通りとなります。
工夫点としては「Orderby([Related 受注情報明細s],[商品])」を用いている点です。これにより、シンプル(に見えないかもですが。。)に表現でき、他の帳票でも流用しやすい記載になっています。
1行毎に説明
このままでは、分かりづらいかと思いますので、1行づつ分解して説明します。
01 <<Start:Orderby([Related 受注情報明細s],[商品])>>
02 <<COUNT(
03 SPLIT(
04 ANY(
05 SPLIT(
06 (" , " & (Orderby([Related 受注情報明細s][商品],[商品コード])) & " , ")
07 ,(" , " &[商品] & " , ")
08 )
09 )
10 ," ,")
11 )>>
12 ・・・
13 <<End>>まずは、核となる6行目をから説明を開始します。
06 (" , " & (Orderby([Related 受注情報明細s][商品],[商品コード])) & " , ")Orderby([Related 受注情報明細s][商品],[商品コード])は、明細データを商品コード順にソート(並び替え)をしています。
例えば、以下のような商品コードの体系であった場合、ソートされた結果は、
A10000
A20000
A30000
B10000
B20000
B10000
C10000
C20000
C30000
D10000のようになるはずです。
ただし、実際は改行されておらず「カンマ」で結合された状態となっています。
A10000,A20000,A30000,B10000,B20000,B10000,C10000,C20000,C30000,D10000そのソート結果 の行頭と行末に、カンマ「,」で文字列結合しています。
,A10000,A20000,A30000,B10000,B20000,B10000,C10000,C20000,C30000,D10000,次に5~8行目を説明します。
05 SPLIT(
06 (" , " & (Orderby([Related 受注情報明細s][商品],[商品コード])) & " , ")
07 ,(" , " &[商品] & " , ")
08 )このままでは分かりづらいので、具体的な値に置き換えます。
例えば、3行目の商品はソートされており「A30000」になっています。
そのため以下のようになっています。
05 SPLIT(
06 (,A10000,A20000,A30000,B10000,B20000,B10000,C10000,C20000,C30000,D10000,)
07 ,(,A30000,)
08 )これが実行されSPLITされると、以下の2つに分割されます。
[,A10000,A20000] [B10000,B20000,B10000,C10000,C20000,C30000,D10000,]この結果、以下となっておりANY()により1つめの配列が選ばれるので、
01 <<Start:Orderby([Related 受注情報明細s],[商品])>>
02 <<COUNT(
03 SPLIT(
04 ANY(
[,A10000,A20000] [B10000,B20000,B10000,C10000,C20000,C30000,D10000,]
09 )
10 ," ,")
11 )>>
12 ・・・
13 <<End>>このままでは、
01 <<Start:Orderby([Related 受注情報明細s],[商品])>>
02 <<COUNT(
03 SPLIT(
[,A10000,A20000]
10 ," ,")
11 )>>
12 ・・・
13 <<End>>となり、さらに「カンマ」でSPLITされると
01 <<Start:Orderby([Related 受注情報明細s],[商品])>>
02 <<COUNT(
[],[A10000],[A20000]
11 )>>
12 ・・・
13 <<End>>となり、それをCOUNT()した結果は、以下の通り「3」となります。
01 <<Start:Orderby([Related 受注情報明細s],[商品])>>
02 << 3 >>
12 ・・・
13 <<End>>つまり、3行目の商品「A30000」に「3」を取得できるため、連番を取得できるわけです。